Chapter 4: Top-Down Parsing
A top-down parsing algorithm parses an input string of tokens by tracing out the steps in a leftmost derivation.
- Backtracking parser: try different possibilities for a parse of the input, backing up an arbitrary amount in the input if one possibility fails. More powerful but way much slower. Not covered in the course.
- Predictive parser: attempts to predict the next construction in the input string using one or more lookahead tokens.
- Recursive-descent parsing: suitable for handwritten parsers.
- LL(1) parsing (processes the input Left to right, uses Leftmost derivation, and 1 symbol of input to predict the direction of the parse): not used nowadays, but easy to understand.
- Both parsing require the computation of lookahead sets called First and Follow sets.
4.1 Top-Down Parsing by Recursive-Descent
Consider the grammar rule factor -> ( exp ) | NUMBER.
Suppose there is a match procedure that matches the current next token token with its parameter expectedToken, advancing the input if it succeeds, and declares error otherwise:
procedure match (expectedToken);
begin
if token = expectedToken then
getToken; // advance input
else
error;
end if;
end match;
Then the procedure for recognizing factor can be written:
procedure factor;
begin
case token of
(: match( ( );
exp; // assume defined
match( ) ); // may raise error
NUMBER:
match(NUMBER);
else error;
end case;
end factor;
4.1.2 Repetition and Choice: Using EBNF
ENBF is designed to mirror closely the actual code of a recursive-descent parser. So it’s better to translate the grammar into ENBF in advance. For example, the if statement:
if-stmt -> IF ( exp ) statement [ ELSE statement ]
This indicates we put off the choices until the else part.
procedure ifStmt;
begin
match(IF);
match( ( );
exp;
match( ) );
statement;
if token = ELSE then
match(ELSE);
statement;
end if;
end ifStmt;
For repetition, e.g. exp -> term { addop term }:
procedure exp;
begin
term;
while token = + or token = - do
match(token); // this will definitely match
term;
end while;
end exp;
Left associativity which is implied by the curly brackets can be maintained by performing the operations as we cycle through the loop. e.g.
while token = + do
match ( + );
temp := temp + term;
end while;
Note that token must be set before the parse begins, and getToken (or a procedure that calls it) must be called just after a successful test of a token.
4.1.3 Further Decision Problems
Problems of the recursive-decent method:
- It may be difficult to convert a grammar from BNF to EBNF.
- When dealing with
A -> α | β | ..., it may be difficult to decide which choice to use if bothαandβbegin with nonterminals. (This requires the First set ofαandβ). - When writing code for
A -> ε, we might need to know what tokens can legally come after the nonterminal A, since such tokens indicate that A may appropriately dissappear at this point in the parse. (This requires the Follow set of A). - The First and Follow set helps with early error detection.
4.2 LL(1) Parsing
4.2.1 Overview
Use a parsing action table.
- The first column numbers the steps.
- The second column shows the contents of the parsing stack with the bottom of the stack to the left, indicated by
$. - The third column shows the remaining input to be parsed.
- The fourth column describes the action taken in this step.
An example: Parse () with the grammar rule S -> ( S ) S | ε.
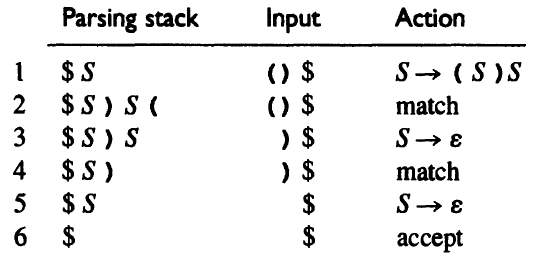
Actions include:
- Replace a nonterminal A at the top of the input stack by a string α using the grammar rule choice
A -> α.- The nonterminal A is popped from the parsing stack, and the tokens in the string α are pushed to the parsing stack in reverse order.
- Match a token on top of the stack with the next input token.
- The matched token is popped from both the parsing and the input stack.
- If the parsing stack and the input stack are both empty, we accept the input string.
To construct a parse tree with LL(1) parsing, we modify the stack to contain pointers to the constructed nodes rather than terminals and nonterminals themselves.
4.2.2 The LL(1) Parsing Table and Algorithm
- If a nonterminal A is at the top of the parsing stack, a decision must be made (which grammar rule to choose).
- If a terminal is at the top of the parsing stack, it is either matched, or an error occurs.
LL(1) parsing table: a table M[N, T]. N is the set of nonterminals in the grammar, T is the set of terminals or tokens, and the table entry M[A, α] is a set of production choices that can be used to produce α from A.
Production choices are added to the table according to the following rules:
- If
A -> αis a production choice, and there is a derivationα =>* aβ, whereαis a token, then addA -> αto the table entryM[A, a]. - If
A -> αis a production choice, and there are derivationsα =>* εandS$ =>* βAaγ, whereSis the start symbol andais a token (or$), then addA -> αto the table entryM[A, a].
LL(1) grammar: A grammar is an LL(1) grammar if the associated LL(1) parsing table has at most one production in each entry.
e.g. The parsing table for the simplified if statements:
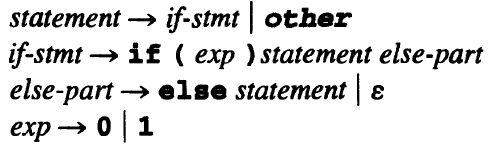
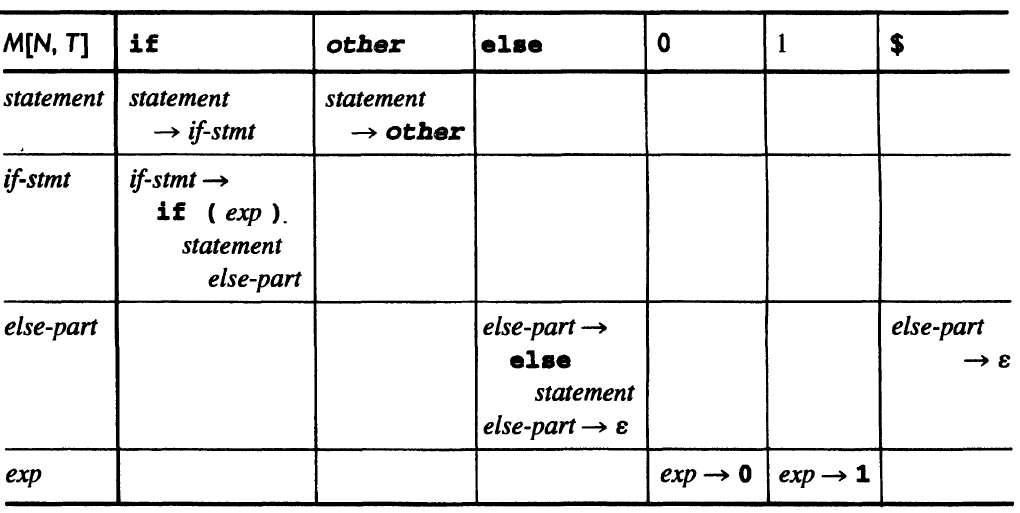
The two entries in M(else-part, ELSE) corresponds to the dangling else problem, so this is not an LL(1) grammar.
4.2.3 Left Recursion Removal and Left Factoring
These are two useful techniques that can turn a grammar into an LL(1) grammar (but they don’t always work).
Left recursion removal
- Immediate left recursion: the left recursion occurs only within the production of a single nonterminal. e.g.
exp -> exp addop term | term. - Indirect left recursion: e.g.
A -> B b | ...; B -> A a | ...
For immediate left recursions in the form of A -> A α | β, we rewrite them as
A -> β A'
A' -> α A' | ε
For general immediate recursions of the form A -> A α1 | A α2 | ... | A αn | β1 | β2 | ... | βm, where non of the β1, ..., βm begin with A, rewrite the grammar as
A -> β1 A' | β2 A' | ... | βm A'
A' -> α1 A' | α2 A' | ... | αn A' | ε
For general left recursions (without cycles and ε-productions), we pick an arbitrary order for all the nonterminals of the language A1, ..., Am, and eliminate all left recursions that does not increase the index of the Ai’s (Ai -> Aj γ with j <= i).
for i := 1 to m do
for j := 1 to i-1 do
replace each grammar rule choice of the form Ai -> Aj β by the rule
Ai -> α1 β | α2 β | ... | αk β, where Aj -> α1 | α2 | ... | αk
is the current rule for Aj
remove the immediate left recursions of Ai
e.g. For the grammar:
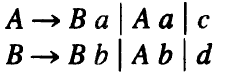
The converted grammar without left recursion:
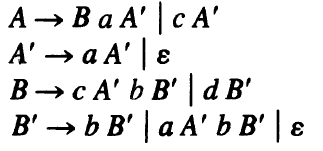
After conversion, the left associativity will be lost. The result of the left subtree must be passed to right subtree to maintain left associativity, see P161.
Left Factoring
For grammars like A -> a b | a c, where b and c share no common prefix, rewrite the rule as
A -> a A'
A' -> b | c
For more complicated situations, use the following algorithm:
while there are changes to the grammar do
for each nontermial A do
let α be a prefix of maximal length that is shared
by two or more production choices of A
if α != ε then
let A -> α1 | α2 | ... | αn be all the production choies of A
and suppose that α1, ..., αk share α, so that
A -> α β1 | ... | α βk | α(k+1) | ... | αn,
the βj's share no common prefix, and
the α(k+1), ..., αn do not share α
replace the rule A -> α1 | α2 | ... | αn by the rules
A -> α A' | α(k+1) | ... | αn
A' -> β1 | ... | βk
4.2 Syntax Tree Construction in LL(1) Parsing
Rather difficult to adapt LL(1) parsing to construct syntax trees, because:
- The structure of the syntax tree can be obscured by left factoring & left recursion removal.
- The parsing stack only represents predicted structures, not structures that have been actually seen. Thus, the construction of syntax tree nodes must be delayed to the point when structures are removed from the stack.
- This requires an extra stack to be used to keep track of syntax tree nodes and that “action” markers be placed in the parsing stack to indicate when and what actions on the tree stack should occur.
Workaround: a value stack + action marker (#). A value stack stores the intermediate values of the computation. When a match occurs, the matched symbol is pushed to the value stack. When the action marker is encountered, action is performed on the value stack (e.g. adding the top two numbers). See P167 for example.
4.3 First and Follow Sets
4.3.1 First Sets
Definition:

The pseudocode for finding the first sets of nonterminals:

In the absence of ε-productions, the algorithm is much simpler:

Definition: A nonterminal A is nullable if there exists a derivation
A =>* ε.Theorem: A nonterminal A is nullable if and only if First(A) contains ε. (Use induction on the length of a derivation.)
4.3.2 Follow Sets
Definition:

Note:
- ε is never an element of a Follow set
- Follow sets are only defined for nonterminals
- Definition of Follow sets work on the right of production rules. (A production
A -> αhas no information ifαdoes not containA)
The pseudocode for computing the Follow set:

4.3.3 Constructing LL(1) Parsing Tables
Using First and Follow sets:

Theorem:
