
复杂声明、多维数组、字符串指针……

C 指针很有用、很复杂、很危险。接下来的几个问题都与指针有关,在此整理,希望帮助自己理解。
复杂声明
读取顺序
我们来看这个声明:
int a;
该语句声明了一个变量 a,类型是 int。再来看这个声明:
int *a;
该语句声明了一个变量 a,它是指向 int 的指针。再看这个:
int a[3];
该语句声明了一个变量 a,它是一个大小为 3 的数组,每个元素的类型是 int。最后看这个:
int a(int x, int *y);
该语句声明了一个函数 a,其参数为 int 型的 x 和指向 int 型的指针 y,返回类型为 int。
以上声明是 C 中最基础的内容。由上,我们可以发现 *(表示指针)、[数字](表示数组)、(形参表)(表示函数)是声明中的关键符号。把它们嵌套起来会发生什么?来看这个:
char (*(*a[3])(int x, char (*y)[5]))[5];
这是一个合法的声明语句。它声明了什么?首先我们需要了解以上符号的优先级:
- 括号。用括号括起来的部分优先运算。
- 后缀的
[数字]与(形参表)。离变量名近的优先运算。 - 前缀的
*。
根据括号—后缀—前缀的顺序,我们可以归纳出一个「右左法则」的算法:
- 找到声明语句中的第一个变量名(即找出该语句声明的变量名,而不是函数形参名),读取它。
- 从已读取部分的右边开始,依次序读取
[数字]或(形参表),直到遇到右括号为止; - 从已读取部分的左边开始,读取
*,直到遇到左括号为止; - 跳出括号,返回步骤 2。
- 直到最后剩下一个类型名。
按顺序理解信息
按照这个顺序,每一步读取的信息,都需要下一步来详细说明。比如,如果第一步读到 (形参表),那么我们知道这是一个函数(还知道了它的形参表)。那么这个函数返回什么类型?如果下一步读到 *,说明函数返回一个指针。那么这个指针指向什么类型?如果再下一步读到 [数字],说明指针指向的是一个数组(还知道了数组的长度)。那么这个数组存储的是什么类型?……边读边问,直到读完为止。
这种方法可以叫做「连环发问法」。让我们结合实例分析一下:
int *a[3];
首先,我们找到变量名 a。向右读取,遇到 [3]。我们立即可以断定,a 是数组,且长度为 3。问:存储什么的数组?
右边读到了头,我们倒转读左边,遇到 *。答:存储指针的数组。问:指针指向什么类型?
还剩下一个类型名,int。答:指向 int 类型。所以,a 是存储 int 指针的数组,长度为 3。我们把存储指针的数组叫做指针数组。
下一个例子:
int (*a)[5];
首先,我们找到变量名 a。向右读取,遇到括号。掉头向左读取,遇到 *。我们断定 a 是指针。问:指向什么的指针?
跳出括号,向右读取,遇到 [5]。答:指向数组的指针,该数组长度为 5。问:数组存储什么类型?
还剩下一个类型名,int。答:指向 int 类型。所以,a 是指向[长度为 5 的 int 数组]的指针。我们把指向数组的指针叫做数组指针。
来一个带函数的例子:
int (*a)(int *b);
首先,找到变量名 a。向右读取,遇到括号。掉头向左读取,遇到 *,表示 a 是指针。问:指向什么?
跳出括号,向右读取,遇到 (形参表),答:指向函数。问:函数返回什么?
还剩下一个类型名 int,答:返回 int。对于形参表内的元素,再单独分析即可(这里是一个指向整数的指针)。最后得到:a 是函数指针,该函数返回 int,形参表是一个指向 int 的指针。
最后我们来看最开始的例子:
char (*(*a[3])(int x, char (*y)[5]))[5];
首先找到变量名 a。向右读取遇到 [3],a 是数组。问:存储什么?
向左读取遇到 *。答:存储指针。问:指向什么?
跳出括号向右看,遇到 (形参表)。答:指向函数。问:返回什么?
遇到括号,向左读取 *。答:返回指针。问:指向什么?
跳出括号,向右读到 [5]。答:指向数组。问:存储什么?
还剩下类型名 char,答:存储 char。再分析之前的形参表,有:a 是含有 3 个元素的数组,该数组存储[指向函数的指针],该函数返回指向[含有 5 个元素的字符数组]的指针,其形参表是[一个整数,和一个指向[含有 5 个元素的字符数组]的指针]。
用 typedef 简化声明
我们发现,在这个声明中,函数的返回值和形参表中的一个参数都是「指向[含有 5 个元素的字符数组]的指针」。这种情况下,我们可以用 typedef 语句简化声明。typedef 的作用就是为给定类型取一个别名。用法很简单:先为这个类型写一个声明,然后在最前面加上 typedef,再把声明中的变量名换成想取的别名即可。例如,我们想为「指向[含有 5 个元素的字符数组]的指针」取一个别名,先写一个普通的声明:
char (*a)[5];
在声明语句前加上 typedef,再把 a 换成我们想要的别名(这里是 ptr_str),就得到 typedef 语句:
typedef char (*ptr_str)[5];
那么,上面的那个声明就可以简化为:
ptr_str (*a[3])(int x, ptr_str y);
这样就容易理解多了。
有时我们会用 const 限定符来限定声明的对象,使其不能被修改。在复杂声明中,const 作用于哪个符号?如果 const 在声明起始,那么它作用于类型名;如果 const 位于中间,那么它作用于它左侧的 * 或类型名。例如 const float *p; 和 float const *p; 都表示该指针指向的 float 值不可被修改;而 float * const p; 表示该指针本身不能被修改。
要说明的是,一般的程序中并不会遇到如此复杂的类型。但是,若能理解这个例子,那么声明一些简单的复合类型时就绝对不会出错了。
多维数组和高阶指针
数组名与 const 指针
最基础的知识点:
- 每个数组的名称都可以看作指向该数组首个元素的
const指针。(我们后面会详细讨论「看作」) - 若
n是整数,那么p[n] = *(p + n)。
一个例子:
int a[5] = {0, 1, 2, 3, 4};
int* p = a;
p++;
因为 a 可看作指向 a[0] 的 const 指针,所以它可以直接赋给 p。所不同的是,由于 a 被看作 const 指针,所以 a 不能被修改,而 p 可以。p 自加后, p[2] = *(p + 2) = *(a + 1 + 2) = *(a + 3) = a[3] = 4。
二维数组元素表示法
定义一个二维数组:
int a[3][5] = {
{0, 1, 2, 3, 4},
{5, 6, 7, 8, 9},
{10, 11, 12, 13, 14}
};
如果我们用前面的方法解释,a 是一个含有 3 个元素的数组,分别为 a[0]、a[1] 和 a[2] ,它们每个都是含有 5 个元素的 int 数组。由于数组名可看作指向数组首个元素的指针,所以a 可看作指向 a[0] 这个数组的指针,a[0]、a[1] 和 a[2] 分别可看作指向 a[0][0]、a[1][0] 和 a[2][0] 的指针,即 int 指针。画图表示:
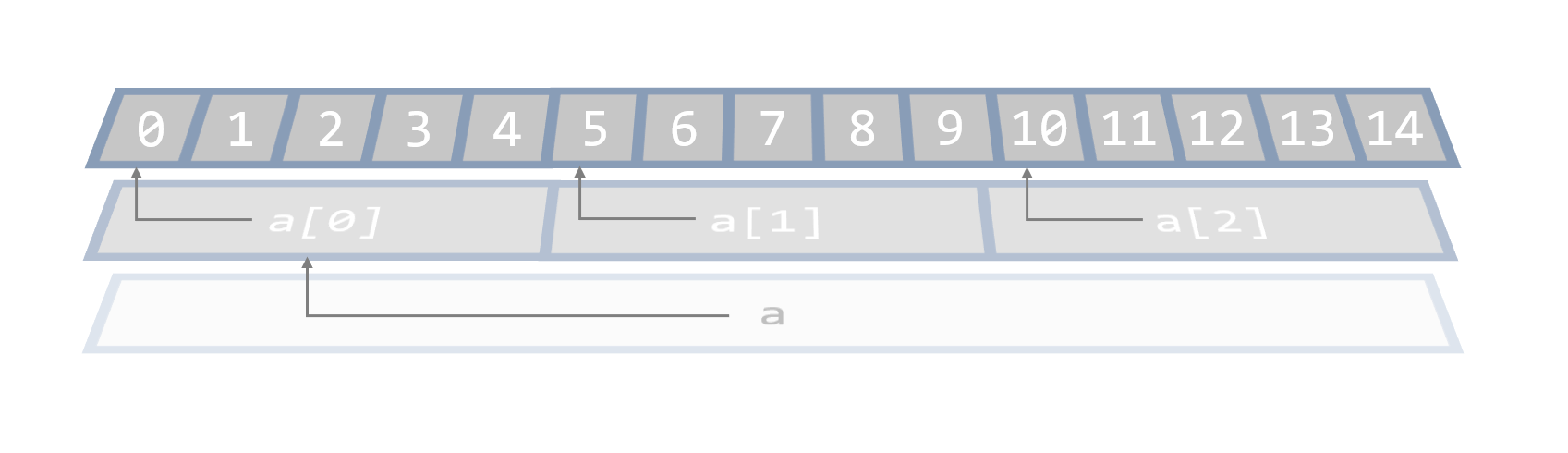
要注意,虽然我们一般把这个二维数组理解成 3 行 5 列,但在内存中它其实只有一维,是一段连续空间。
如果我们要表示「13」这个元素,有哪些方法呢?
我们当然可以直接采用数组表示法,表示为 a[2][3];也可以先用数组表示法找到第三个数组的首地址,然后加上 3 个位置,再解引用,表示为 *(a[2] + 3);还可以先找到 a,然后加上 2 解引用得到第三个数组的首地址,再加上 3 解引用得到 *(*(a + 2) + 3)。
弄懂二维数组,三维及以上的数组就不难理解了。
二维数组、二级指针、数组指针和指针数组
这些概念有些难以区分和使用。下面是一些声明:
int aa[3][5] = {
{0, 1, 2, 3, 4},
{5, 6, 7, 8, 9},
{10, 11, 12, 13, 14}
}; /* 声明二维数组 */
int **pp; /* 声明二级指针 */
int (*pa)[5]; /* 声明数组指针 */
int *ap[3]; /* 声明指针数组 */
我们首先来看关于二维数组和二级指针的一个常见误区。很多人认为,既然数组名可以看作指针,那么二维数组名也可以看作二级指针,所以我们可以直接赋值:
pp = aa;
然而报错:
[Warning] assignment from incompatible pointer type
这说明,二维数组名和二级指针是绝对不能划等号的。为了方便说明,我们先退回一维数组说起:
int a[4] = {0, 1, 2, 3};
int *p;
p = a;
a[2] = 5;
尽管经常将数组名看成指针,但数组和指针完全是两回事。实际上,a 的类型是 int [4],即长度为 4 的 int 数组。a 指的是放置长度为 4 的 int 数组的这一整段内存单元(而不是首元素或它的地址); p 的类型是 int *,p 指代放置 int 指针的这一段内存单元。
只不过,在大多数时候,a 这个数组名被隐式转换为该数组首元素的地址。在这里,a 是一个 int 数组,其首元素的地址自然可以赋给 int 指针,所以 p = a; 这个语句没有问题的。再比如,用数组表示法表示 a[2] 的时候,a 先被转换成首元素地址,然后 a[2] 被替换成 *(a + 2),表示首元素后面的第二个元素,即第三个数 2。
但是要注意,这样的隐式转换不是任何时候都成立,比如使用 sizeof 运算符来计算对象大小时。执行以下语句:
printf("a has a size of %d bytes, while ", sizeof(a));
printf("p has a size of %d bytes.", sizeof(p));
在我的电脑上输出的结果为:
a has a size of 16 bytes, while p has a size of 8 bytes.
a 是长度为 4 的 int 数组,int 现在一般是 4 字节,所以 a 占 4×4=16 字节。p 是指针,我使用 64 位操作系统,所以指针占 8 字节。在这里,a 是没有转换为首元素地址的。
还要再说明一点:对于高维数组,这种隐式转换一次只转换一级。这就很容易解释为什么 aa 不能赋给 pp:因为在赋值语句 pp = aa; 中,aa 被隐式转换为首元素(即 aa[0])的地址,而 aa[0] 本身也是一个数组(不再转换为指针),其类型是 int [5]。pp 是 int 的二级指针,只接收类型为 int * 对象的地址,当然不能用 aa[0] 的地址来赋值了!
在关乎类型的情况下,指针就是指针,数组就是数组,一定要注意区分。
如果我们确实要为 aa 取一个别名,就要用到数组指针了。刚才我们声明了 int (*pa)[5];,pa 就是一个数组指针,可以存储类型为 int [5] 对象的地址。前面说过,aa 会被隐式转换成 aa[0] 的地址,它是可以直接赋给 pa 的:
pa = aa;
在这里,aa 被看作指向 aa[0],而pa 确实指向 aa[0],所以 pa 和 aa 是等价的。那我们就可以用 pa 来指代 aa 进行操作了,比如 pa[1][3] 就是 aa[1][3],即 8。
但有一点不同:我们现在可以修改 pa 的值,让它指向其他位置。如:
pa++;
现在 pa 指向 aa[0] 的下一个,即 aa[1]。这时的 pa[1][3] 就变成了原来的 aa[2][3],即 13。
二维数组作函数形参时也要用到数组指针。如果我们要把二维数组名 aa 作为函数实参,由于调用函数时 aa 会被转化为指向首元素(类型为 int [5])的指针,那么声明该函数时就该这样写:
T func(int (*pa)[5]); // 而不是 int **pa
也可以写成:
T func(int pa[][5]);
我们再来看指针数组。指针数组就是一个数组,其元素都是指针。在二维数组 aa 中,aa 是由 aa[0]、aa[1] 和 aa[2] 组成的数组,它们都可看作指向 int 元素的指针,所以 aa 也可以看作是指针数组。
现在我们定义了 int *ap[3];,ap 是一个指针数组。如果我们要把 aa 这个指针数组赋给 ap,怎么办?
ap = aa;
这么写当然是错的:ap 被看作一个 const 指针,所以不能被赋值。我们只能这样写:
int i;
for (i = 0; i < 3; i++) {
ap[i] = aa[i];
}
现在,我们尽可以用 ap 来代替 aa 表示原数组中的元素。比如,ap[2][3] 和 aa[2][3] 一样,都表示13,因为 ap[2][3] 可以写成 *(ap[2] + 3),而 ap[i] = aa[i]。
同样,我们现在可以修改 ap[i] 的值。假若我们执行下列语句:
ap[1] += 2;
ap[2]++;
ap[1] 原本指向 aa[1][0],加 2 后指向它后面的第二个,即 aa[1][2],为 7。同样地,ap[2] 指向 11。这时, ap[2][3] 就是 11 后面的第三个数,14。
另一种情况,假若我们执行下列语句:
int *tmp;
tmp = ap[1];
ap[1] = ap[2];
ap[2] = tmp;
这时 ap[1] 指向 10,ap[2] 指向 5。ap[2][3] 实际上是 aa[1][3],即 8。我们后面会看到,在字符串操作中,指针数组是经常使用的。
还有一点:由于指针数组 ap 的名字被转换为其首元素的地址,而其元素是指针,所以 ap 可被看作是一个二级指针。它可以直接被赋值给 pp:
pp = ap;
pp 指向 ap[0],它是一个 int 指针。pp 可以自加,将指向 ap[1]。
字符串指针
我们知道,字符串其实就是 char 数组,以 '\0' 作为结束符。不过它本身也有一些有趣的特性。
字符串字面量
char *s = "I'm a string!";
在这里,用双引号括起来的 I'm a string! 就是一个字符串字面量。编译程序时,编译器会自动在其后面加上 '\0'。程序运行时,这一字符串被存放进内存中,如果没有指针指向它,我们就只能用 "I'm a string!" 来访问它。"I'm a string!" 就如同这个字符串的名字,我们甚至可以这样写:
putchar("I'm a string!"[4]);
会输出 a。
现在我们将 s 指向了该字符串(的首字符),就可以用 s 来操作了,如 s[0] 是 'I',s[7] 是 't'。但是,不能通过 s 来修改字符串的值,因为字符串字面量是 const 常量。若强行修改,程序会异常退出。
但如果这么定义:
char t[] = "I'm a string!";
就不同了。程序运行时,先将 "I'm a string!" 存储到内存中,再开辟一段大小刚好的内存空间,将 "I'm a string!"(包括后面的 '\0')拷贝到此空间。这时,字符串 t 是可以被修改的,但修改的是 t 本身,而不是字符串字面量 "I'm a string!"。如果在方括号中加数字,就指定了这段内存空间的大小。注意,一定要确保能够容纳后面的字符串字面量和末尾的 '\0'。
在同一程序中,相同的字符串字面量往往会被当作同一个来存储。来看以下代码:
char *a = "I'm a string!";
char *b = "I'm a string!";
printf("%p %p", a, b);
在我的电脑上输出如下:
0000000000404000 0000000000404000
可以看到,两个 "I'm a string!" 其实被存储到了内存的同一位置。
用指针数组处理多个字符串
char *l[100];
我们现在定义了一个指针数组 l,长度为 100。处理字符串用指针数组比用二维数组方便得多,因为指针数组是可以修改值的。例如在字符串排序中,我们可以直接交换指针数组中两个指针的值,而不用费劲将两个字符串交换,如图:
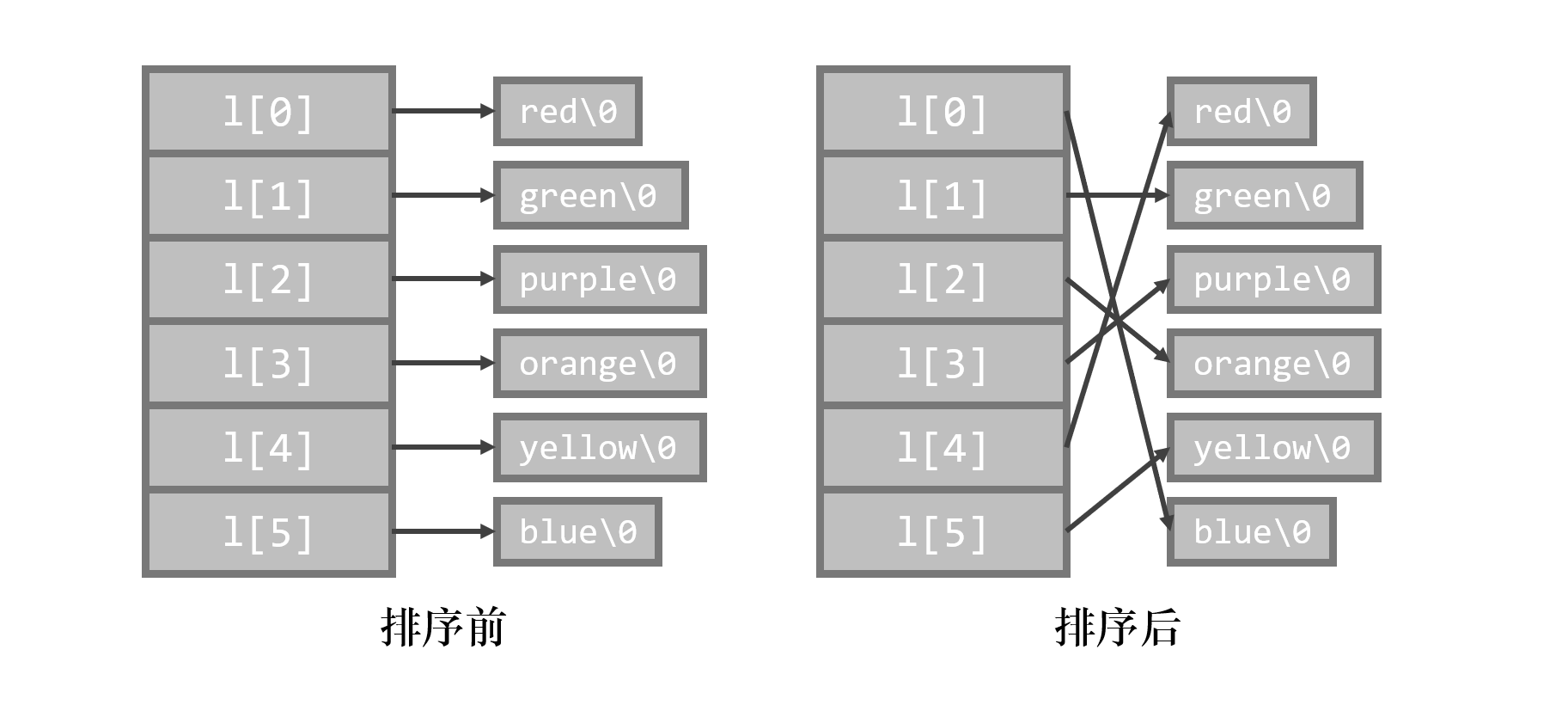
现在问题是:如何读取这 100 个字符串?
int i;
for (i = 0; i < 100; i++)
scanf("%s", l[i]);
这种写法错误,且十分危险!l 中的每一个元素都还是未初始化的指针,怎么能写入数据?
一种正确的方法,是再定义一个二维字符数组,用它来读取,再把指针数组指向它。这样比较占内存,因为每个字符串可能长度不一,我们在定义二维数组时需要照顾最长的字符串。我们可以用 malloc 函数,灵活地为每个字符串分配内存:
int i;
char s[1000] /* 假定字符串的长度最大可能为 1000 */
for (i = 0; i < 100; i++) {
scanf("%s", s);
l[i] = (char *)malloc(sizeof(char) * (strlen(s) + 1));
strncpy(l[i], s, 1000);
}
这样,对于每个字符串,其分配到的大小刚好合适,不会浪费空间。
本文所有内容都来自课件、《C Primer Plus》和中文互联网,一定有很多不严谨或者错误的地方。我觉得最重要的内容就是复杂声明的阅读方法,和数组与指针的区别,剩下的内容都是知识的运用。祝使用指针愉快!



留下评论
注意 评论系统在中国大陆加载不稳定。